BrunnerCTF 2025 - Infra writeup
BrunnerCTF 2025 exceeded expectations with 1100+ teams and 2800+ users. We built a custom scalable infrastructure using off-the-shelf and custom-made components, IaC and DevOps practices. This post dives into how it was built, what worked, and where it can be improved.


BrunnerCTF 2025 was the first edition of BrunnerCTF, held by Brunnerne, from 22nd August @ 14:00 CEST to 24th August @ 14:00 CEST.
The CTF targeted beginner and intermediate CTF teams, with a few challenges for the most hardcore CTF teams.
The CTF lineup is starting out strong, with more than 2800 registered players and 1400 registered teams; the CTF had more players than we could have ever imagined. In total, 1158 teams got on the scoreboard.
Looking at the feedback from the event, we received praise for the crew, challenges and infrastructure for the event. Indicating that we did something right.
But how did we achieve this with our first CTF? What was our infrastructure? And did everything go so smoothly?
TL;DR
Key facts about the infrastructure and event:
- Ran a large-scale CTF, with 2800 registered players and 1400 registered teams, resulting in 600 instances running simultaneously.
- Developed an Infrastructure-as-Code setup, that utilizes CTFd and KubeCTF for CTF platform and instancing.
- Utilized DevOps and GitOps principle, to design and implement a challenge development pipeline, that allows for continous deployment and updates of challenges.
- Ran the platform in Kuberntes, hosted on Hetzner for cheap - Allowing us to scale with ease. Totalling 265.18€ in server costs.
Challenges we faced:
- Outage during the first 22 minutes due to misconfigured Traefik deployment.
- Tried to ensure outage resiliance, by utilizing Clustered Redis - Which CTFd was not designed for and had it erroring during the CTF.
- Got rate limited by Google, due to the large amount of emails being sent for signups.
- Limited alerting about struggling shared instances.
Key elements that we will continue to work on:
- Developer workflow, streamlining and simplifying challenge development even more, alongside simplifying the deployment system.
- Develop custom alerting and better dashboards for insights into instanced challenges.
- Utilize instancing for all challenges.
The numbers
To understand the CTF, let's start with some numbers.
When we planned the CTF, our expectation was around 300-1500 players.
In total, at the end of the CTF, 2860 users and 1491 teams were registered on our platform, whereof 1158 teams received at least 10 points, the minimum amount possible.
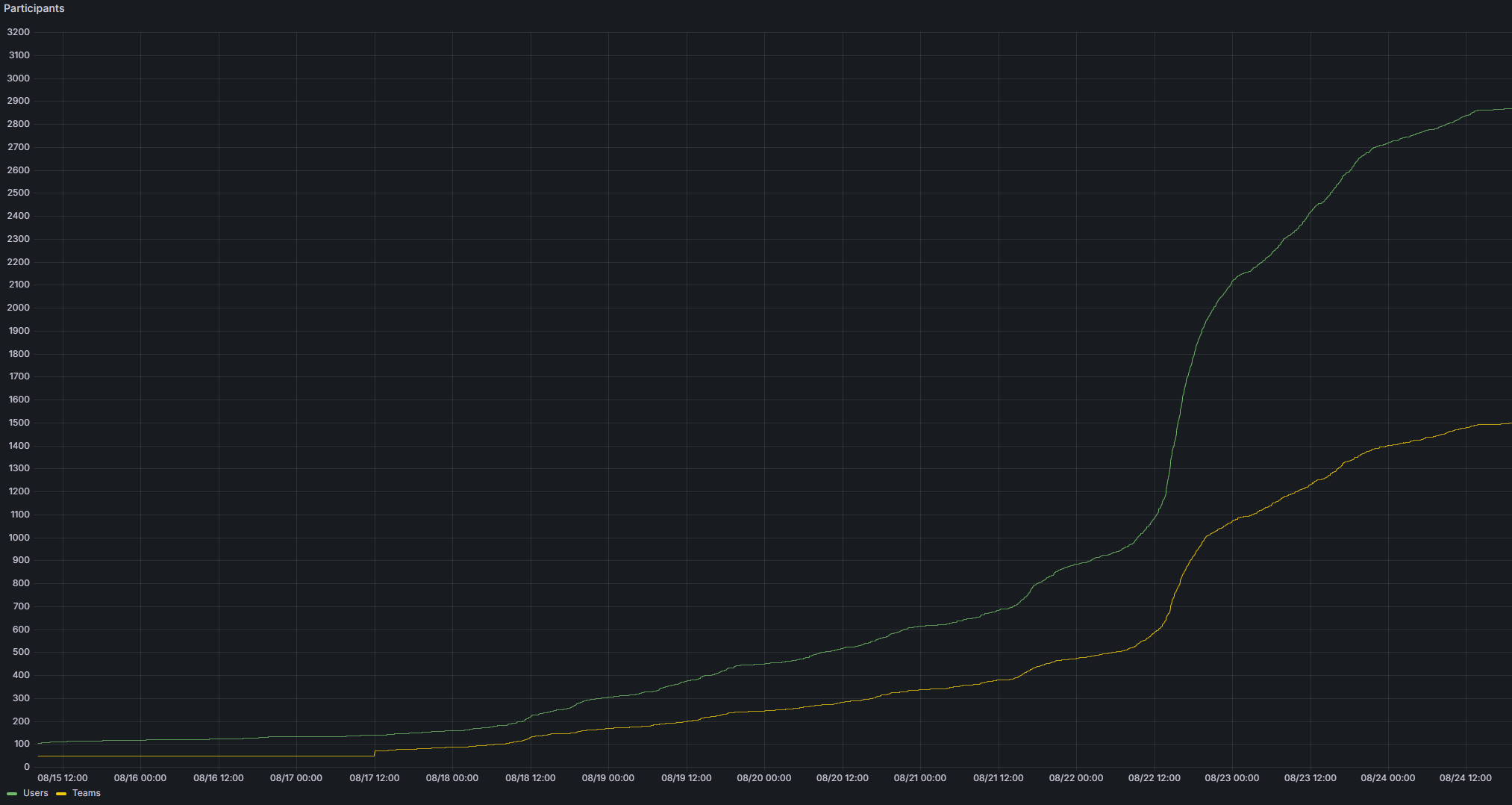
From our data, we can see that a large portion of participants joined during the CTF or very close to the CTF start. But we did see a portion of teams registering in advance.
For the event, our amazing challenge developers had whipped up 83 challenges across 10 categories. 21 of these challenges were in "Shake & Bake" - our beginner track. The other categories were Boot2Root (6), Crypto (9), Forensics (5), Misc (10), Mobile (3), OSINT (4), Pwn (6), Reverse Engineering (9) and Web (10).
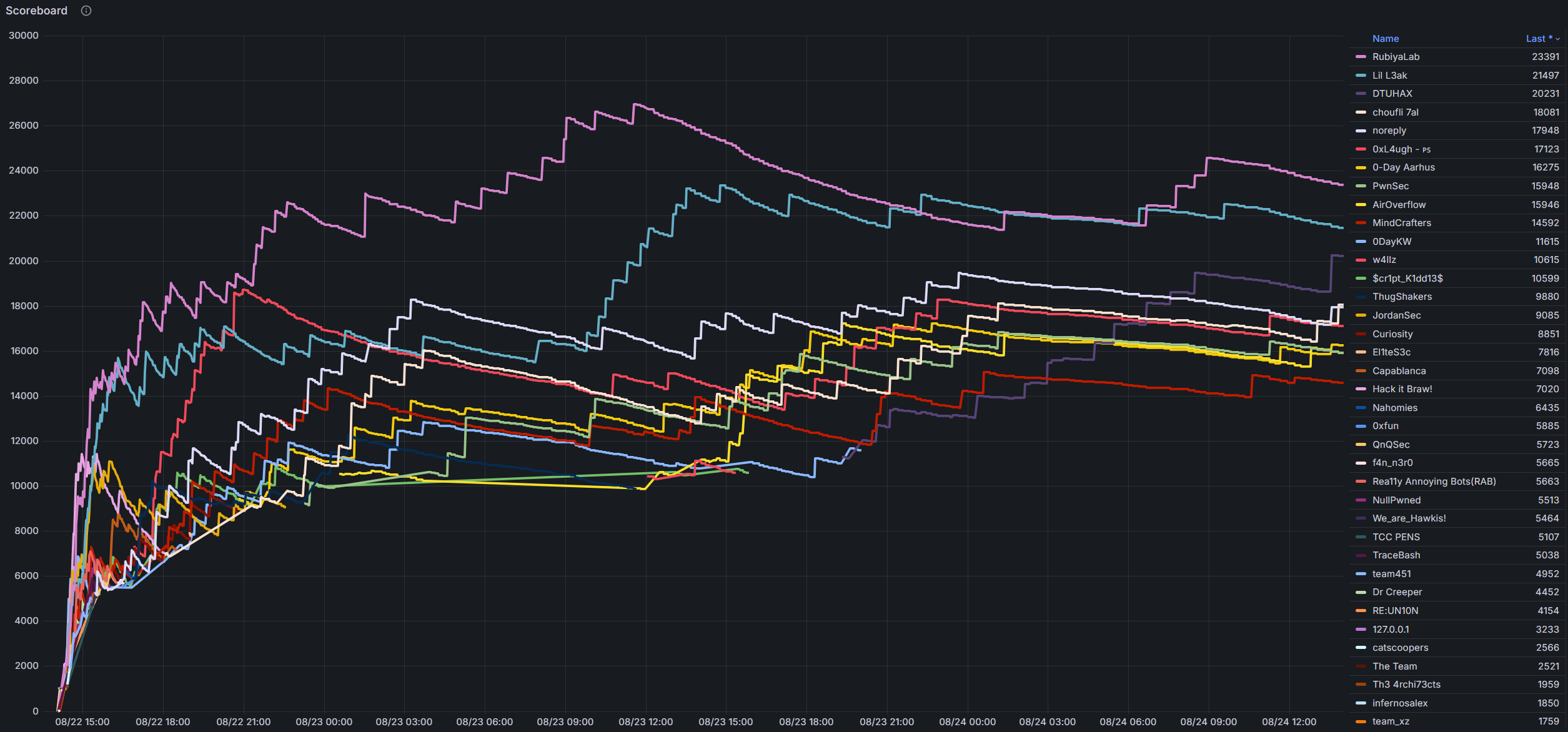
All challenges were solved at least once, with the winning team, RubiyaLab, solving 79 challenges out of the 83 available.
Our most failed challenge was the OSINT challenge, Traditional Cake, with ~8.000 failed attempts.
We had three types of challenges: Static, Shared and Instanced. Static being challenges needing only the description on our platform, and maybe some files. Shared is a remote host shared by all teams, and Instanced is a unique remote for each team.
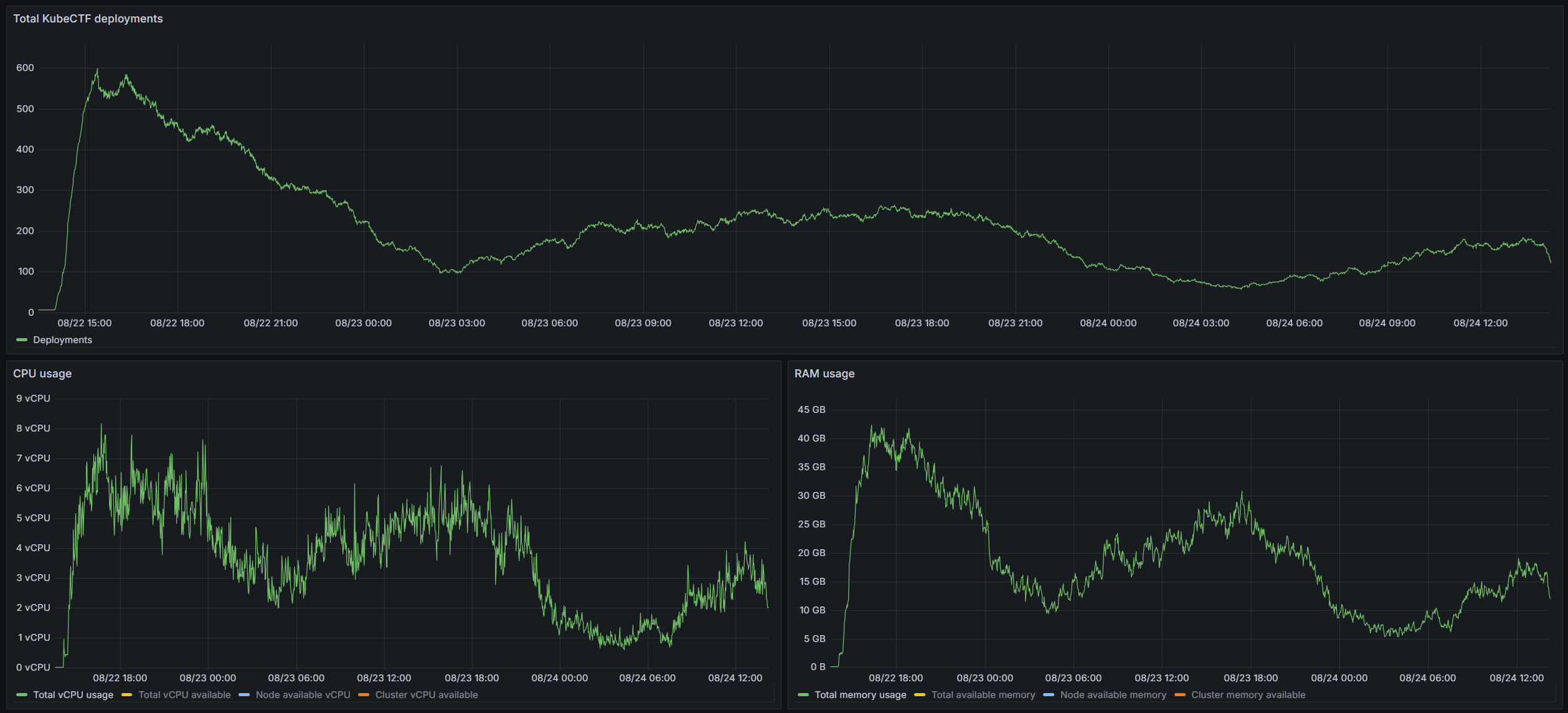
At peak, we had 600 instances running, which in total used ~8 vCPU and ~43 GB of RAM. In the first hour, roughly 750 instances were deployed.
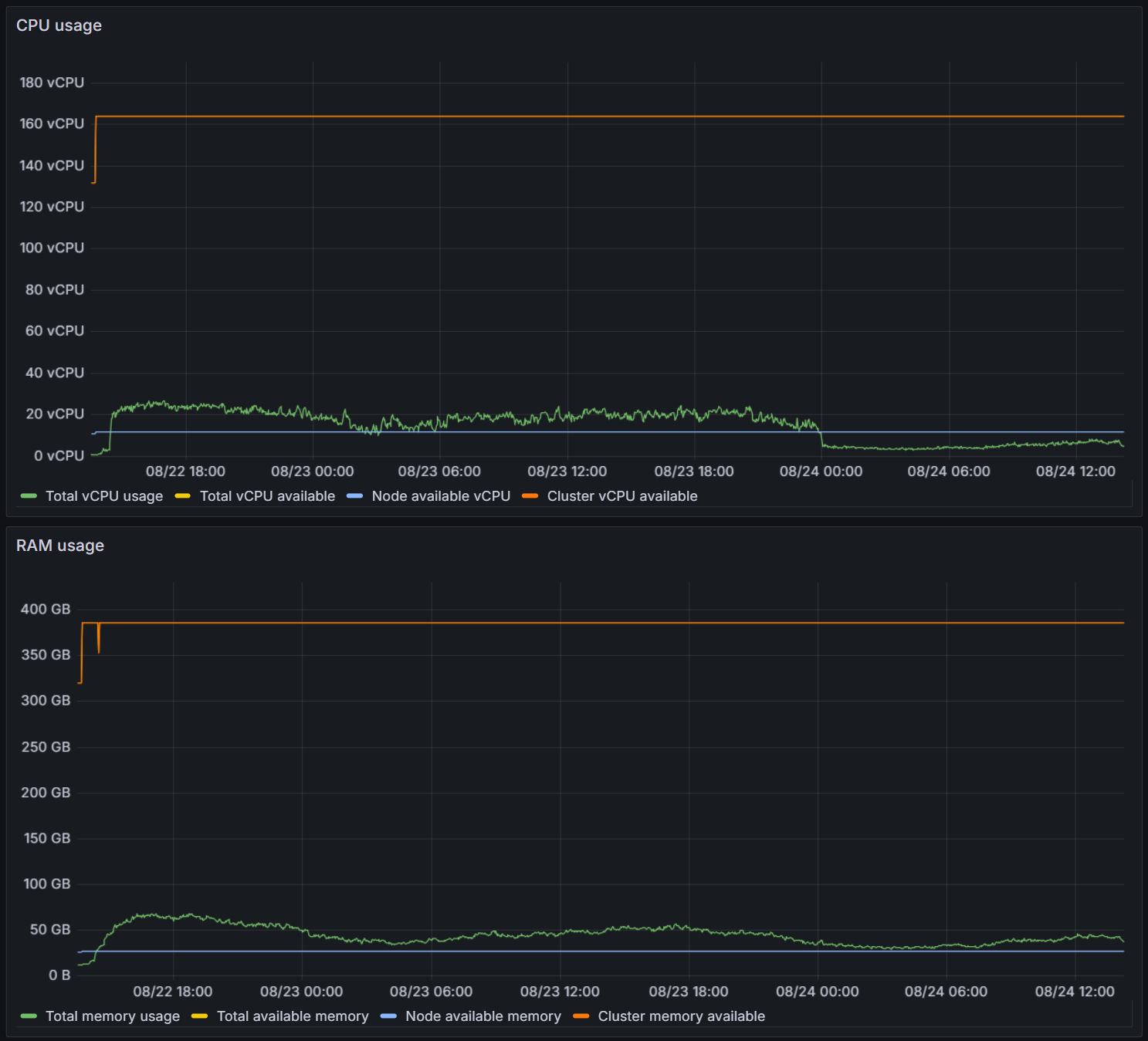
For the CTF we had spun up a cluster with a total of 164 vCPU and 386 GB RAM, distributed across 14 nodes.
When looking at the whole cluster, we peaked at ~26 vCPU and ~67GB RAM. Leaving us with an enormous headroom.
Looking at connection details, we had between 1500 and 2500 open connections at any given point, as reported by our load balancer.
When looking at HTTP requests, we had more than 35 million requests, peaking at roughly 160.000 requests per minute (2.666 per second) across the whole platform. We even spotted multiple instances receiving more than 1 million requests each.

For CTFd, Cloudflare reported 3 million requests.
Digging into the type of requests, we can see that our challenges were hit with multiple bruteforcing tools, such as gobuster, Fuzz Faster U Fool and Feroxbuster.

I could go on and on about the stats. But I think you have a good picture and can draw some interesting conclusions already.
The infrastructure
For BrunnerCTF, we choose to combine off-the-shelf CTF systems with custom-made systems, compiling them into an Infrastructure-as-Code project, as well as building a challenge development pipeline.
Yes, this is where the DevOps bingo card starts filling up.
But what that means is that for BrunnerCTF, we have tried to use existing systems, such as CTFd for the challenges and scoreboard, and KubeCTF for the challenge instancing. We have then added our own systems on top, allowing us to create and change challenges on GitHub and push them directly to CTFd and KubeCTF. Then, for simplifying future setups, we have automated the setup and teardown of the infrastructure, requiring only a configuration file to deploy the CTF infrastructure (and some correctly configured Hetzner projects and S3 buckets).
While deploying it all on a scalable hosting platform, using Kubernetes.
To develop challenges, we have made multiple developer tools, which the next section will dig into.
Developer tooling
We wanted to make it extremely easy to make challenges and ensure that challenges were standardised, while providing machine-readable formats that we could use for automation, which I will come back to later.
With this goal, we ended up making several tools for our challenge developers.
If we start at the beginning of the lifecycle of a challenge, Discord.
We used Discord to discuss challenges, and the natural step was to integrate it into the workflow itself. We built a bot that can update the development status of the challenge and bootstrap the code needed for the challenge, directly from Discord. Making it extremely easy to get started.
From here, two elements were created: A GitHub issue and a branch with an associated PR. The GitHub issue allowed us to track the status of the challenge and display all challenges in a GitHub project.
The branch and PR allowed us to version control the challenge and store it in a central repository. When a challenge was done and verified through reviews, it was merged into our development branch and later into the main branch.
To document each challenge, we created a challenge schema, containing the needed information for the challenge, such as challenge name, type, flags, Dockerfiles, and points.
With the challenge data, like the Dockerfiles, we automated the build of Docker images for each challenge, allowing multiple images to be created for one challenge, storing them all in GitHub Container Registry.
We also automated handout creation, with all files in a dedicated directory, being automatically zipped into a challenge handout.
These elements allowed challenge developers to only worry about the challenge, and not how to build or package their challenges.
Deployment pipeline
The core fundamental of the infrastructure we have built is to automate as much as possible. This, therefore, also includes the deployment of challenges.
There are two main aspects of deploying challenges for a CTF: challenge information and the remote host.
Deploying challenge information entails taking information from the GitHub repository, reformatting it, and putting it into the CTF platform - CTFd.
To do this, we used the data compiled into the challenge schema and formatted it as configuration files, which could then be automatically pushed into our cluster as a ConfigMap. In the cluster, a CTFd manager then reformats the information and updates CTFd with the challenges.
Deploying the remote host entails compiling a deployment manifest and either deploying that correctly or templating it such that KubeCTF can deploy it.
Here, the challenge data is once again used, together with a customizable template, to generate a deployment file. For static challenges, we generated Helm charts, and for instanced challenges, we generated simple Kubernetes manifest files.
Helm charts were not used for instanced challenges, as KubeCTF templating interferes with Helm.
In order to push it into our cluster, we utilised ArgoCD, which is a "declarative, GitOps continuous delivery tool for Kubernetes". This means that it takes Kubernetes manifest files and Helm charts from GitHub and deploys them in the cluster automatically. This allows continuous deployment of our configuration and deployments.
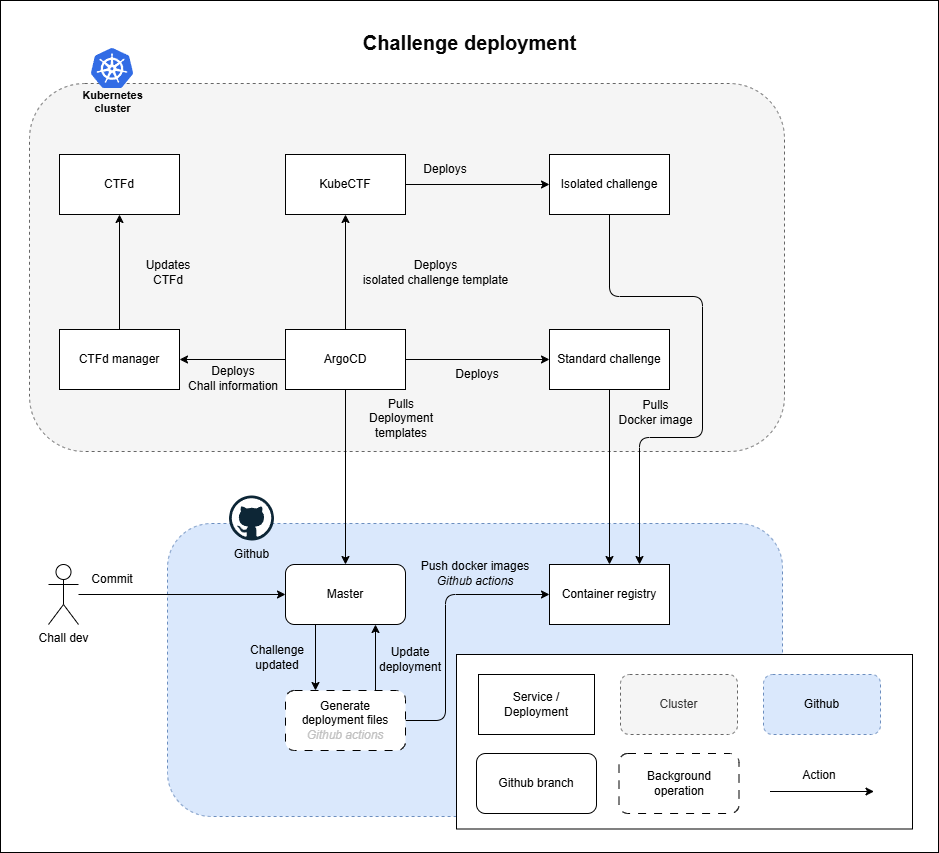
The cluster
Now that I have mentioned "the cluster" and Kubernetes, it is time to talk about how we hosted the CTF - The actual deployed infrastructure.
As implied, we used Kubernetes as the container orchestration engine. We chose it, as it allows us to deploy the infrastructure and containers across multiple nodes, and allows for continued operation, even if one or more nodes fail, as well as scale to more nodes if more resources are needed.
As a fair warning: Kubernetes is complex, and anyone who wants to replicate needs a decent knowledge of Kubernetes to build and run a similar setup.
To deploy the Kubernetes cluster, we used Kube-Hetzner, an open source project to deploy Kubernetes in Hetzner, utilising Terraform as the deployment engine. The project is very well made, with a lot of good defaults. Definitely worth checking out if you want to run Kubernetes on Hetzner.
For the cluster, we had four node pools:
- Control planes - Running 3x CPX31 (4 vCPU, 8GB RAM)
- Agents - Running 3x CCX33 (8 dedicated vCPU, 32 GB RAM)
- Challs - Running 7x CPX51 (16 vCPU, 32 GB RAM)
- Scale - Running 1x CPX51 (16 vCPU, 32 GB RAM)
The control planes handle the Kubernetes control plane and are in charge of orchestrating the cluster. Agents are the main workhorse, handling all general workloads, such as monitoring, deployment engines, CTFd, etc. Challs nodes handle the challenge containers, both shared and instanced. Scale is an autoscaled node pool, which automatically adds more nodes through Cluster Autoscaler, if there are containers which cannot be scheduled in the cluster.
All nodepools together had 164 vCPU and 376 GB RAM. With 128 vCPU and 256 GB RAM allocated for challenges.
As core services in the cluster, we ran Traefik for proxy, Filebeat for logs and a Prometheus-Grafana stack for monitoring. Logs were offloaded to an ELK stack on a secondary server to persist logs outside the cluster.
CTFd
For scoreboard and challenge information, we used CTFd.
CTFd is a well-established CTF platform; however, it is known to require some resources and fine-tuned configuration.
We opted to deploy CTFd in the cluster to be able to scale during the CTF.
To deploy CTFd in Kubernetes, we used a clustered database and a clustered cache. For the clustered database, we used MariaDB, which was managed by mariadb-operator, which was set up to deploy a 3-node MariaDB Galera cluster.
For clustered caching, we used clustered Redis, which was deployed and managed through a redis-operator.
This allowed for easy deployment and failover handling.
CTFd were deployed and managed through ArgoCD and Kubernetes manifest files on GitHub.
Instancing
When looking at the CTF, one of my requirements for the CTF was that we would be able to have instanced challenges. This is usually only done by more established CTFs and requires a good bit of infrastructure in order to dynamically deploy instances for each team.
However, we are in luck. CTFs have become popular, resulting in multiple instances of solutions already existing. CTFer.io has made a collection of some instancing systems; however, we stumbled across DownUnderCTF's infrastructure writeups, and their instance manager: KubeCTF.
The instancing system works by utilising Kubernetes resource definitions to store the deployment template for each challenge, and then deploying these when a team requests an instance. Utilising the Kubernetes orchestration to manage each deployment, requiring few resources from the challenge manager to deploy and maintain.
Each instance was designed, with one deployment, with one or more services and ingresses, depending on whether they required multiple entrypoints - Such as Single Slice Of CakeNews.
To handle "offline" and "loading" instances, we utilised Traefik. Traefik allows for multiple services to handle the same route, with more specific routes taking precedence. KuberCTF is deployed with a fallback page that displays an "Offline challenge" message. For the "Challenge is starting", we utilised the errors middleware, which allows us to return custom pages, such as when the service is not yet available. Making it possible to distinguish between when a challenge is not yet started, and is currently starting.
Misc
For some other interesting facts:
- The system is configured to take backups every 15 minutes, with backups being offloaded to multiple physical sites, to improve resilience.
- S3 is used for handouts, offloading file downloads to a separate environment.
- With the use of IaC, it is possible to deploy a fully configured infrastructure in less than 30 minutes, often taking less time. While a safe shutdown takes less than 10 minutes.
- Besides Cloudflare, the infrastructure uses European service providers, keeping all data in the EU.
Combining it all
To deploy it, four different Terraform projects were used to manage the infrastructure: Cluster, Ops, Platform and Challenges.
Cluster handles the cluster setup. Ops deals with the underlying operations, in terms of logging, monitoring and other essential systems, such as operators and ArgoCD. Platform deals with CTFd and associated systems. And lastly, Challenges handles the remote hosts, both shared and instanced.
Drawing it up, looks something like this:
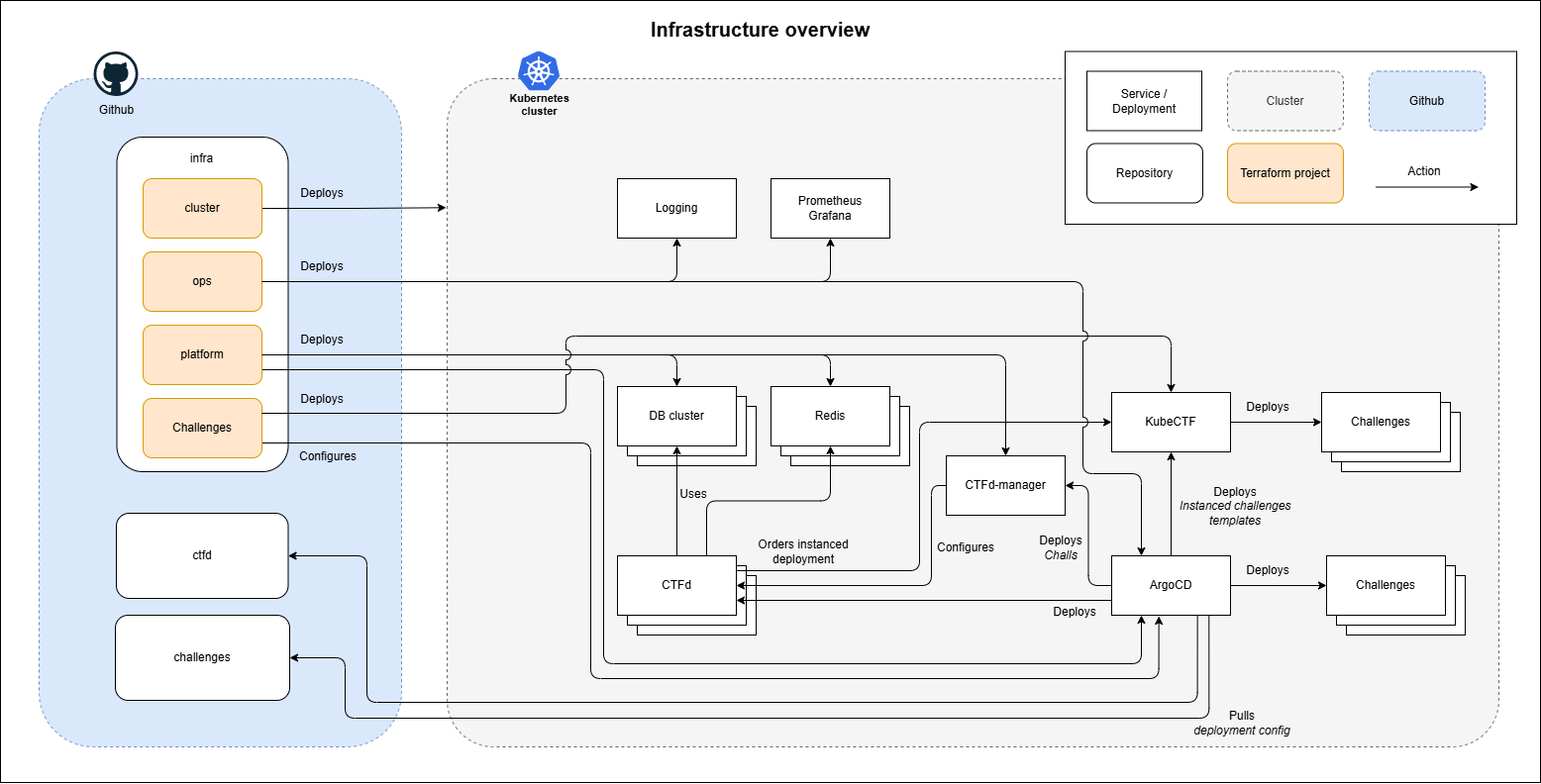
For those interested, the reason why we use four different Terraform projects is due to the fundamental design of Terraform. Terraform retrieves the status of each resource that it orchestrates. If you use CRDs, it is not possible to deploy manifests using these in the same Terraform project (or not easily at least). It also allows for splitting responsibility.
For the infrastructure, we used OpenTofu, but have referred to it as Terraform, as they work the same.
The cracks and improvements
Even though the infrastructure ran smoothly for the majority of the CTF, there were cracks and things we would like to do differently next year.
Are we down?
We did not survive the "first 5 minutes" of the CTF, not even the first 20 minutes - That's what this graph of uptime says at least.
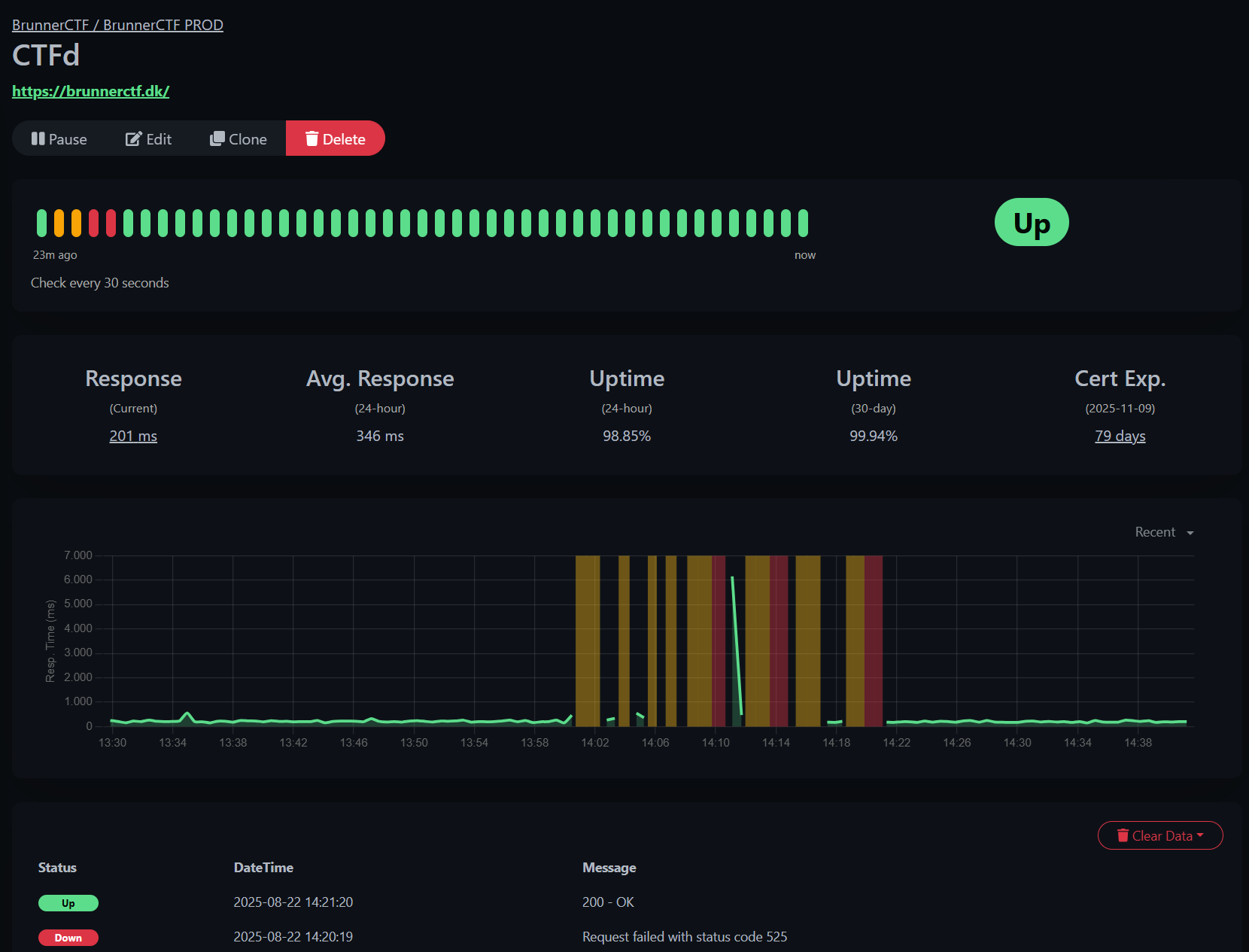
The first 22 minutes show a partial outage. This was the one thing we wanted to avoid.
The intermittent nature of the outage caused the crew to ask, "Are we down?" - Because some of the crew could get through to the platform, while others couldn't.
Our first instinct was to look at CTFd, as we thought this would be the culprit - It has always been written up as the one to fuck it up. But no, we didn't see any load spikes. No CPU throttling. No major errors in the logs. Nothing indicates it is the issue.
Okay, so CTFd didn't cause this. We then looked at our load balancer. But this reported no issues. And we were well within the limits of our plan (LB21). But to be safe, we upgraded to the largest load balancer. But we still saw failing requests.
As the next step in the chain, we turned to look at Traefik.
IT WAS STRUGGLING.
With Kube-Hetzner, Traefik is set up to scale; however, due to two things, this did not happen. So three instances of Traefik handled all of the load. Due to the number of requests being sent, Traefik got overloaded, causing it to handle requests slowly. So slowly that the liveness probes in Kubernetes timed out, causing Kubernetes to see the instances as down and therefore automatically restarting the individual pods.
To fix this as fast as possible, we manually edited the Traefik deployment to allow Traefik to use 8 cores and lots of RAM.
The effect was immediate. Errors were gone, and our Discord, which participants happily mocked us on for our infrastructure being down, became eerily quiet.
Traefik however? It now uses 4-6 cores per pod, across 3 replicas, with our agent nodes running on full throttle with about 80-95% CPU usage. Originally, each Traefik pod had about 400m CPU.

The cause of the scaling issue was due to the configuration of a sidecar to offload logs. This sidecar did not have any specified resources. As the autoscaler, therefore, could not see how many resources the pod should use, it simply couldn't autoscale, and instead just errored out. Leaving Traefik at the minimum number of replicas - 3 replicas - instead of scaling up to the 10 replicas that it was allowed to scale to.
Due to tainting of the challenge nodes, we had also limited Traefik to run only on our agent nodes, forcing all traffic to go through these nodes. This created an increased load on these servers, but did not cause the outage.
After implementing resource requests and limits for the logging sidecar, the CPU usage of Traefik dropped by more than 90%. This can be seen in the cluster-wide CPU usage, where it drops at 24-08-2025 00:00 - The time when we deployed this fix.
We don't know why Traefik used so many resources, and why it dropped so drastically after a more permanent fix.
Why Clustered Redis is probably not the best idea
While CTFd was not the cause of our outage, we did see issues. CTFd was deployed with Clustered Redis as cache. This configuration is not natively supported by CTFd, and we therefore implemented a custom cache configuration for CTFd.
We chose to go with clustered Redis in order to have quick failover, in case a node failed during the CTF. However, it turns out that you cannot just point any usage of Redis to a clustered Redis server. So during the CTF, CTFd continuously crashed due to a key retrieval error within the Flask caching library. The only reason that we were not offline was because we ran 6 replicas of CTFd, allowing for multiple of them to be offline at the same time, without causing any downtime.
For the next CTF, we need to look into a fix for this, most likely by moving to another Redis setup that is not clustered, but can handle quick failover if a pod or node failure happens.
Sending 6.000 emails
Email is not easy. But we choose to have email verification for the event regardless. This resulted in more than 6.000 emails being sent. To not handle this ourselves, we choose to use Brevo. They delivered a rock-solid performance.
However, halfway through the CTF, Google began to defer our emails. Shortly thereafter, the support tickets and comments about not receiving emails began rolling in.
It took roughly 30 minutes to locate what "deferred" meant - The logs indicated that Google was rate-limiting us. We had simply sent too many emails to them.
However, the rate limit was domain-bound. The simple fix was therefore to switch the email domain during the CTF - Not the best, but it got the emails working.
There are not many solutions to this. Google and other mail providers document that if you need to send many emails, you have to ramp up slowly. We probably ran into the rate limit late, due to us opening registration quite early, and therefore ramping up slowly with that.
We recommend that anyone else sending emails for CTFs have multiple domains ready and an easy system to change the from domain during the CTF.
Alerts and insight
One of the things we didn't get to tweak before the CTF was our monitoring and alerting system.
As mentioned earlier, we used Prometheus and Grafana as our main monitoring stack. It worked well, and we had some custom graphs and dashboards. Giving insight into the overall health of the platform and the challenges deployed.
However, during the CTF, we had to dig into raw queries to retrieve deployed instances for individual teams or backtrack from an instance to a team.
These are, therefore, prime targets for improvements. Especially easily retrieving team instances, their health and usage.
We had, however, not deployed any custom alerts. This results in us leveraging the default Prometheus alerts in the deployed stack.
These did indicate forever restarting containers and severe outages.
It even reported CPU throttling sometimes.
CPU throttling was actually an issue in some instances and shared remotes. However, the default alert for CPU throttling requires another alert to trigger. Which didn't happen for the majority of the time.
We discovered about 24 hours into the CTF that our shared remotes did not have enough resources, and that some instances were being hammered.
One goal for the next CTF is therefore to improve these alerts, to allow for more appropriate alerts and timing.
Instancing everywhere
On the topic of shared remote being overloaded - Why did we have shared remotes?
As mentioned earlier, instanced remotes are quite novel and not used in all CTFs. They often require a lot of resources. The argument is often, why run 100 remotes, when 1 can do the job?
We found out why: Because everyone will be hitting the same remote, which will affect the performance of each other's connections. This is especially an issue when some players run automated scripts that cause CPU usage to spike. If the traffic to the instance is not controlled, such as with rate limits, it might be possible for a few players to overload a shared remote for the rest of the players.
With instanced remotes, if one player decides to go wild, they are restricted to the instance and have a very limited risk of affecting other instances. Making it easier to control and limit players.
Instances also allow tracking players, and if needed, block them from attacking the instances.
With the instancing system used for BrunnerCTF, we have proven that the infrastructure can easily scale to handle a large number of instances without issues.
A valid reason to run shared remotes might be if the minimum resource usage for the remote far exceeds what a single or multiple users can cause when attacking the remote.
Improving developer workflow
While we did create a streamlined and impressive developer workflow, it wasn't perfect.
The largest issue with the developer workflow is that we did not have a way to test a challenge on the cluster before it was fully ready. We saw one case where the challenge had to be completely redone, as the infrastructure setup could not accommodate the challenge. This was discovered as the challenge was done, and was tested on our development cluster. Yikes.
We therefore want to implement a way to test a challenge on the infrastructure, before it is ready. Maybe even with an automatic PR deployment system?
Some challenges require massive files. This could, for example, be a full disk image.
Git and GitHub are not the best options for handling files that are multiple gigabytes large.
We therefore opted to store them outside of GitHub. However, this was set up late, and forced the challenge developer to store the file themself until this was set up.
With some larger files being stored in Git and with a lot of changes, the Git repository reached 1 GB in size at the end of the CTF.
We would like to find a better solution for the larger files, but currently, no solution is in the works.
And that leads us to the next issue: When developing a challenge with the developed workflow, you have to clone the whole repository, with all challenges in it, to develop a new challenge.
This is both heavy, cumbersome and gives you a lot of other files, which can be confusing. It is also easy to end up making changes to another challenge.
We haven't found a good way to solve this yet, but we hope to address this issue for the next event.
The last issue is the deployment files. Currently, all deployment files for a challenge are stored within the challenge directory, both templates and rendered templates. This is a good practice with GitOps. However, every time a challenge is changed in any way, it auto-generates all deployment files. This allows for the deployment of the new version and insight into what and how it is deployed. But for review, it takes up a lot of space, and it can be hard to see if the changes are auto-generated files or actual changes.
Deployment files are specified on a per-challenge basis, which did cause some issues when global changes had to be made. For the next event, we might look into storing the deployment templates in a central system and rendering the deployment files using only the challenge schema.
Pricing
So what does this infrastructure cost? An arm and a leg?
Far from it, in fact. Hetzner, the cloud provider we used for BrunnerCTF 2025, is cheap and simple.
The total cost of our infrastructure, including the development cluster, amounted to 265.18€. 🤯
An incredibly low number for the amount of resources that we had available.
If you look only at our production infrastructure, and take the cost from when we opened for signup (start August) to when the event finished (25th of August), the total cost sums to 127.45€
That's a full Kubernetes cluster, with load balancers and S3 storage for handouts and backups.
We decided to have a development cluster for roughly ~1.5 months, which allowed us to test the infrastructure and challenges. Critical in ensuring high-quality infrastructure and challenges. Well worth the 137.73 €.
We believe that it is possible to lower the cost significantly by not overprovisioning as heavily as we did and running the production and development cluster for a shorter period. However, we believe that it is worth the cost to run it in this configuration.
A huge thanks to Hetzner for sponsoring the infrastructure for BrunnerCTF 2025! You can learn more about Hetzner at htznr.li/BrunnerCTF
Conclusion
BrunnerCTF 2025 exceeded all expectations, with more than 1100 teams and 2800 users participating. Absolutely wild first edition of BrunnerCTF
And that makes the amazing work and large amount of time that our challenge developers have put into the 83 challenge so worth it!
For the CTF, a large effort was put into making the infrastructure, combining off-the-shelf CTF systems with custom-made systems, hosting it in Kubernetes and deploying it using Infrastructure-as-Code. All while making a development workflow that allows for streamlined challenge development.
The end result is a stable, scalable platform, able to handle a large number of CTF players, participating from around the world at the same time.
As much as we wanted everything to run as smoothly as possible, a few issues did arise, such as a partial outage for the first 22 minutes of the CTF, due to configuration issues.
However, we see BrunnerCTF 2025 as a huge success, but with room for improvement.
Thanks
A huge thanks to the whole BrunnerCTF 2025 crew, which consisted of more than 25 members of Brunnerne. Without these talented people, BrunnerCTF 2025 would not have been possible.
A large thanks goes out to all of the sponsors for the CTF: Bankdata, Campfire Security, CyberSkills and Hetzner.
I hope you found this infrastructure write-up interesting and can use some of the principles and learnings presented. If you want to discuss any of it, we have created an infrastructure channel on our CTF discord: https://discord.gg/yUU9dNq98k
We have decided not to publish the infrastructure code. This may change as we clean up the individual parts. Some of the core systems, such as CTFd, KubeCTF, Kube-Hetzner, Kubernetes and ArgoCD are freely available.
We have released the system under the name CTF Pilot and can be found on GitHub: https://github.com/ctfpilot